Conclusiones
Conclusiones
Los resultados obtenidos con el mejor modelo (el mejor al evaluarlo en el subset de testeo) en el subset de validación fueron:
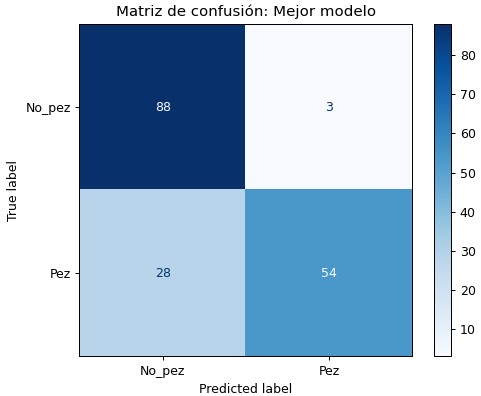
Los modelos implementados tuvieron buen nivel de exactitud y precisión para todas las clases al ser evaluados en el subset de testeo, sin embargo, su performance no fue tan buena al ser evaluados en el subset de validación. Se observó que la exactitud total del modelo bajó de un valor de más de 90 % (para KNN y RF) a un valor de 83% para ambos modelos. Esto típicamente puede darse por tener un modelo sobreentrenado, creo que este no es el caso.
Al contrario, en este caso la mala performance de los mejores modelos en el subset de validación se debe a que el modelo está subentrenado. Esto es por la construcción del dataset que se utilizó. Este es una lista de objetos, que salen ordenadamente de una lista de imágenes. Los primeros objetos perteneces a las primeras imágenes. Por lo tanto, asumo que el modelo se entrenó con un grupo reducido de imágenes y al pasar al subset de validación donde hay imágenes con características diferentes el modelo pierde su buena performance. Este efecto se da por la dificultad del etiquetado del dataset.
Como conclusión de este proyecto, se puede decir que el método de identificación y conteo de Arowana mediante el uso de imágenes obtenidas por dron arrojó un resultado satisfactorio en el subset de testeo (precisión del 91 % para la clase pez) y un resultado aceptable en el subset de validación (precisión de 67 % para la clase pez).
A continuación, se detalla una lista de pasos a seguir que probablemente logren una mejora significativa del modelo:
a) Aumentar el número de objetos etiquetados correctamente para posteriormente dividir en los subset de Train/Test/Validation
b) Realizar un muestreo estratificado (por imagen a la que pertenece cada objeto y según su clase (pez/no pez)) para construir cada subset, de esta manera nos aseguramos de tener subsets de Train/Test/Validation balanceados y con suficiente variabilidad.
c) Mejorar el pre-procesamiento de la imagen: es posible definir los umbrales de Canny en función de cada imagen, de esta manera se logrará terminar de solucionar el problema de la iluminación no uniforme. Con esto se reducirá el número de objetos detectados que no son objetos en realidad y se mejorarán los bordes detectados de los peces.
d) Intentar definir las mejores y las peores condiciones para la toma de imágenes con dron a través de la exactitud (y otras métricas) del modelo.